粒子/インスタンス化
粒子は3Dビルボードにとても良く似ています。しかし、この二つは次の点が異なっています。
- 通常多くの粒子が存在します。
- 粒子は動きます。
- 現れたり消えたりします。
- 半透明になっています。
これらの違いが問題となります。このチュートリアルではこれを解決する一つの方法を紹介します。他にも多くの方法があります。
多くある粒子
多くの粒子を描く方法のひとつは前のチュートリアルのコードを使うことです。そして各粒子ごとにglDrawArraysを呼びます。これはとても悪い方法で、GTX’512+のようなマルチプロセッサに一つの四角形を描画することに専念させることを意味しています。(明らかに一つしか使われず、99%の効率ロスとなります。)そして二つ目のビルボードを同じように描画します。
明らかに、同じときにすべての粒子を描画することが必要となります。
これにはいくつか方法がありますが、ここでは3つの方法を示します。
- すべての粒子に対して一つのVBOだけを生成します。簡単で、効果的でどのプロットフォームでも動きます。
- ジオメトリシェーダを使います。このチュートリアルの範囲外です。なぜなら50%程度のコンピュータでサポートされていないからです。
- インスタンス化を使う。すべてのコンピュータでは使えませんが、大半のもので使えます。
このチュートリアルでは三番目の選択肢を使います。なぜならこの方法はパフォーマンスと可用性とのバランスがとても良く、一つ目の方法をこの方法に追加するのも簡単だからです。
インスタンス化
インスタンス化はベースメッシュ(この場合2つの三角形によるシンプルな四角形)で、この四角形のインスタンスが多くあるということを意味しています。
技術的には、いくつかのバッファを通して行われます。
- それらのバッファの中にはメッシュを描写するものもある
- それらのバッファの中にはベースメッシュの各インスタンスの粒子を描画するものもある
各バッファに何を入れるかは多くの選択肢があります。ここでは次のようなものを考えます。
- メッシュの頂点用の一つのバッファ。インデックスバッファではなく、6個のvec3で二つの四角形と一つの四角形を示します。
- 粒子の中心用の一つのバッファ
- 粒子の色用の一つのバッファ
これらは基本的なバッファで、次のように作ります。
// このVBOは粒子の4頂点を持っている。
// インスタンス化のおかげで、すべての粒子で共有できます。
static const GLfloat g_vertex_buffer_data[] = {
-0.5f, -0.5f, 0.0f,
0.5f, -0.5f, 0.0f,
-0.5f, 0.5f, 0.0f,
0.5f, 0.5f, 0.0f,
};
GLuint billboard_vertex_buffer;
glGenBuffers(1, &billboard_vertex_buffer);
glBindBuffer(GL_ARRAY_BUFFER, billboard_vertex_buffer);
glBufferData(GL_ARRAY_BUFFER, sizeof(g_vertex_buffer_data), g_vertex_buffer_data, GL_STATIC_DRAW);
// このVBO粒子の位置とサイズを持ちます。
GLuint particles_position_buffer;
glGenBuffers(1, &particles_position_buffer);
glBindBuffer(GL_ARRAY_BUFFER, particles_position_buffer);
// 空の(NULL)バッファで初期化します。各フレームで後で更新します。
glBufferData(GL_ARRAY_BUFFER, MaxParticles * 4 * sizeof(GLfloat), NULL, GL_STREAM_DRAW);
// このVBOは粒子の色を持ちます。
GLuint particles_color_buffer;
glGenBuffers(1, &particles_color_buffer);
glBindBuffer(GL_ARRAY_BUFFER, particles_color_buffer);
//空の(NULL)バッファで初期化します。各フレームで後で更新します。
glBufferData(GL_ARRAY_BUFFER, MaxParticles * 4 * sizeof(GLubyte), NULL, GL_STREAM_DRAW);
これらは通常、次のようにして更新します。
// OpenGLが描画用に使うバッファを更新する
// CPUからGPUへ向かうデータを流すようなより洗練された意味もありますが、このチュートリアルの範囲外です。
// http://www.opengl.org/wiki/Buffer_Object_Streaming
glBindBuffer(GL_ARRAY_BUFFER, particles_position_buffer);
glBufferData(GL_ARRAY_BUFFER, MaxParticles * 4 * sizeof(GLfloat), NULL, GL_STREAM_DRAW); // Buffer orphaning, a common way to improve streaming perf. See above link for details.
glBufferSubData(GL_ARRAY_BUFFER, 0, ParticlesCount * sizeof(GLfloat) * 4, g_particule_position_size_data);
glBindBuffer(GL_ARRAY_BUFFER, particles_color_buffer);
glBufferData(GL_ARRAY_BUFFER, MaxParticles * 4 * sizeof(GLubyte), NULL, GL_STREAM_DRAW); // Buffer orphaning, a common way to improve streaming perf. See above link for details.
glBufferSubData(GL_ARRAY_BUFFER, 0, ParticlesCount * sizeof(GLubyte) * 4, g_particule_color_data);
これはいつもどおりです。描画の前に次のようにバインドします。
// 一つ目の属性バッファ:頂点
glEnableVertexAttribArray(0);
glBindBuffer(GL_ARRAY_BUFFER, billboard_vertex_buffer);
glVertexAttribPointer(
0, // 属性:0に深い意味はないが、シェーダのlayoutと一致させないといけない。
3, // サイズ
GL_FLOAT, // タイプ
GL_FALSE, // 正規化?
0, // ストライド
(void*)0 // 配列バッファオフセット
);
// 二つ目の属性バッファ:粒子の中心の位置
glEnableVertexAttribArray(1);
glBindBuffer(GL_ARRAY_BUFFER, particles_position_buffer);
glVertexAttribPointer(
1, // 属性:1に深い意味はないが、シェーダのlayoutと一致させないといけない。
4, // サイズ:x+y+z+size => 4
GL_FLOAT, // タイプ
GL_FALSE, // 正規化?
0, // ストライド
(void*)0 // 配列バッファオフセット
);
// 3つ目の属性バッファ:粒子の色
glEnableVertexAttribArray(2);
glBindBuffer(GL_ARRAY_BUFFER, particles_color_buffer);
glVertexAttribPointer(
2, // 属性:2に深い意味はないが、シェーダのlayoutと一致させないといけない。
4, //サイズ:r+g+b+a=>4
GL_UNSIGNED_BYTE, // タイプ
GL_TRUE, // 正規化する。これはunsigned char[4]にシェーダでvec4(float)でアクセスできるようにすることを意味します。
0, // ストライド
(void*)0 // 配列バッファオフセット
);
これもいつもどおり。描画のときに違う処理が必要になります。glDrawArrays(あるいはベースメッシュがインデックスバッファを持っている場合はglDrawElements)を使う代わりにglDrawArrraysInstanced / glDrawElementsInstancedを使います。これらはglDrawArraysをN回呼ぶのと同じです。(Nは最後のパラメータ、ここではParticlesCountを指します。)
glDrawArraysInstanced(GL_TRIANGLE_STRIP, 0, 4, ParticlesCount);
気をつけることは、ベースメッシュ用のバッファは呼ばず、異なるインスタンス用のバッファを呼ぶ点です。これはglVertexAttribDivisorで実現でき、以下にコメントつきのコードを示します。
// これらの関数はglDrawArrays *Instanced* 特有です。
// 最初のパラメータは注目してる属性バッファです。
// 二つ目のパラメータは、複数のインスタンスを描画するときに一般的な頂点属性が進む割合を意味します。
// http://www.opengl.org/sdk/docs/man/xhtml/glVertexAttribDivisor.xml
glVertexAttribDivisor(0, 0); // 粒子の頂点:同じ4頂点を使いまわすので->0
glVertexAttribDivisor(1, 1); // 位置:四角形ごとに一つ(中心)->1
glVertexAttribDivisor(2, 1); // 色:四角形ごとに一つ->1
// 粒子を描画する
// これは(四角形に似た)triangle_stripを何度も描画します。
// これは以下のコードと等価ですがより早いです。
// for(i in ParticlesCount) : glDrawArrays(GL_TRIANGLE_STRIP, 0, 4),
glDrawArraysInstanced(GL_TRIANGLE_STRIP, 0, 4, ParticlesCount);
これまで見てきたようにインスタンス化は本当にいろいろな用途に使えます。なぜならAttribDivisorとして整数をパスできるからです。例えばglVertexAttribDivisor(2, 10)では各10個の連続したインスタンスが同じ色を持ちます。
どういう意味か?
多くのメッシュを変更するのではなく、各フレームで小さなバッファ(粒子の中心)を更新する必要があるだけです。これは4倍の帯域幅が節約されたことを意味します。
生成と消滅
シーンでのほかのオブジェクトとは違い、粒子は高速で生成したりと消滅したりします。新しい粒子を取得したり、古い粒子を無視したりする“new Particle()”のような方法より洗練された方法が必要です。
新しい粒子を作る
ここでは、大きな粒子コンテナを作ります。
// 粒子のCPUでの表現
struct Particle{
glm::vec3 pos, speed;
unsigned char r,g,b,a; // 色
float size, angle, weight;
float life; // パーティクルの寿命。0未満ならば消滅し使用しない
};
const int MaxParticles = 100000;
Particle ParticlesContainer[MaxParticles];
新たな粒子を作る方法が必要です。この関数はParticlesContainerを線形サーチします。これは一般的にはひどいアイディアですが、最後の位置からサーチを始めることにより、通常この関数は迅速に返してくれます。
int LastUsedParticle = 0;
// ParticlesContainerで使われていない粒子を探す。(つまりlife<0)
int FindUnusedParticle(){
for(int i=LastUsedParticle; i<MaxParticles; i++){
if (ParticlesContainer[i].life < 0){
LastUsedParticle = i;
return i;
}
}
for(int i=0; i<LastUsedParticle; i++){
if (ParticlesContainer[i].life < 0){
LastUsedParticle = i;
return i;
}
}
return 0; // すべての粒子が使用中なので、一番最初のものにオーバーライドする。
}
ParticlesContainer[particleIndex] を“life”と“color”と“speed”と“position”で満たします。 より詳しくコードを見ると、ここでいろいろなことができます。問題は各フレームでいくつの粒子を生成すべきかということです。これはアプリケーション次第で、1秒間に10000個のような大量の新しい粒子を生成することを考えます。
int newparticles = (int)(deltaTime*10000.0);
固定した値になるように切り捨てを行います。
// 1ミリ秒に10個の新しい粒子を生成します。
// しかし60fpsという条件を満たすようにします。
// newparticlesは大きく、次フレームではより長いです。
int newparticles = (int)(deltaTime*10000.0);
if (newparticles > (int)(0.016f*10000.0))
newparticles = (int)(0.016f*10000.0);
古い粒子の削除
ここにはトリックがあります=)
メインシミュレーションループ
ParticlesContainerはアクティブな粒子と死んだ粒子を含んでいます。しかしGPUへ送る必要があるのは生きている粒子だけです。
そこで各パーティクルを繰り返し、生死をチェックして、すべてが問題なければ重力を付加し、最終的にGPU特有のバッファにコピーします。
// 全粒子をシミュレートする
int ParticlesCount = 0;
for(int i=0; i<MaxParticles; i++){
Particle& p = ParticlesContainer[i]; // ショートカット
if(p.life > 0.0f){
// lifeを減らす
p.life -= delta;
if (p.life > 0.0f){
// シンプルな物理をシミュレートします。衝突はありません。
p.speed += glm::vec3(0.0f,-9.81f, 0.0f) * (float)delta * 0.5f;
p.pos += p.speed * (float)delta;
p.cameradistance = glm::length2( p.pos - CameraPosition );
//ParticlesContainer[i].pos += glm::vec3(0.0f,10.0f, 0.0f) * (float)delta;
// GPUバッファを満たします。
g_particule_position_size_data[4*ParticlesCount+0] = p.pos.x;
g_particule_position_size_data[4*ParticlesCount+1] = p.pos.y;
g_particule_position_size_data[4*ParticlesCount+2] = p.pos.z;
g_particule_position_size_data[4*ParticlesCount+3] = p.size;
g_particule_color_data[4*ParticlesCount+0] = p.r;
g_particule_color_data[4*ParticlesCount+1] = p.g;
g_particule_color_data[4*ParticlesCount+2] = p.b;
g_particule_color_data[4*ParticlesCount+3] = p.a;
}else{
// SortParticles()で丁度消滅した粒子をバッファの最後に移します。
p.cameradistance = -1.0f;
}
ParticlesCount++;
}
}
これが結果です。ただし問題点があります。

ソート
チュートリアル10で説明したように、ブレンドを正しくするには後から前面に向かって半透明オブジェクトをソートする必要があります。
void SortParticles(){
std::sort(&ParticlesContainer[0], &ParticlesContainer[MaxParticles]);
}
ここでstd::sortにコンテナのどの粒子を前に置いて、どの粒子を後に置くかを伝える必要があります。そこでParticle::operator<を定義します。
// 粒子のGPUでの表現
struct Particle{
...
bool operator<(Particle& that){
// 一番遠い粒子を最初に描画するように、逆順にソートする
return this->cameradistance > that.cameradistance;
}
};
これでParticleContainerはソートされ、粒子は正しく表示されます。
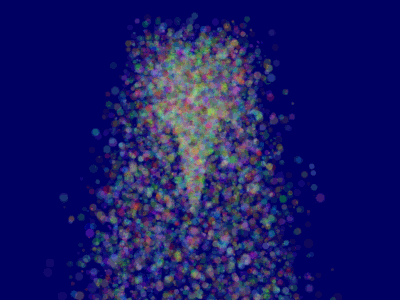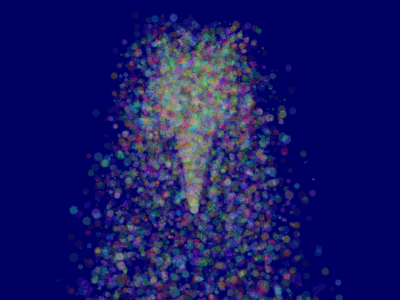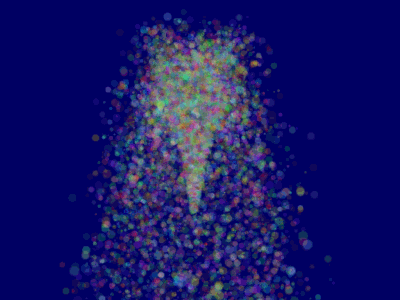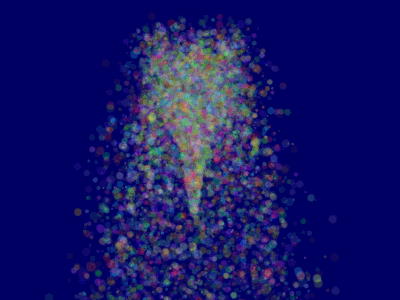
さらに先へ
アニメ粒子
texture atlasによって粒子のテクスチャをアニメーションさせることができます。位置とともにパーティクルの年を送ることで2DフォントチュートリアルでやったようにシェーダでUVを計算します。texture atlasは次のようにします。

複数の粒子システムを扱う
一つの粒子システム以上のものが必要な場合、二つの方法があります。一方は一つのParticleContainerで済ます方法。もう一つはシステムごとにParticleContainerを作る方法。
すべての粒子に対して一つのコンテナしか使わない場合は、ソートを完璧に行えます。欠点としては、すべての粒子に同じテクスチャを使う必要がある点です。これはtexture atlasを使うことで解決できます。(異なるUVを使うように、異なるテクスチャをすべて含んだ一つの大きなテクスチャ)しかしこの方法はエディットしたり使用したりするのに便利ではありません。
パーティクルシステムごとにコンテナを用意する場合、一方で、コンテナ内でのみ粒子のソートが行われます。もし二つの粒子システムがオーバーラップすると乱れ始めます。アプリケーション次第ですが、これはあまり問題ではありません。
もちろんいくつかの粒子システムを組み合わせることも可能です。
粒子の平滑化
すぐに乱れに気づくと思います。 幾何学的に交差するときに、とてもおかしくなります。

(image from http://www.gamerendering.com/2009/09/16/soft-particles/ )
これを解決する一般的な方法は、今描画してるフラグメントが近くにあるかZバッファでテストする方法です。そうならばフラグメントをフェードアウトさせます。
しかし、Zバッファをサンプルする必要があり、通常のZバッファでは不可能です。 そこで描画対象でシーンを描画する必要があります。代わりに、あるフレームバッファから別のバッファへとglBlitFramebufferを使ってZバッファをコピーできます。
http://developer.download.nvidia.com/whitepapers/2007/SDK10/SoftParticles_hi.pdf
フィルレートの改善
現代のGPUの最も大きな制約はフィルレートです。60FPSを許すような16.6ミリ秒のうちに描画できるフラグメント(ピクセル)の総量です。
これは問題で、粒子は大きなフィルレートが必要な典型例で、毎回他の粒子とともに10回も同じフラグメントを再描画しなければなりません。これができなければ上で見たような乱れが生じます。
描画されたすべてのフラグメントのなかには不用なものもあります。例えば境界にあるようなもの。粒子テクスチャはエッジ上で完璧な透明なではあるが、粒子のメッシュはそれらに描画しようとします。そして前とまったく同じ色に色を更新します。
この小さなユーティリティがテクスチャに合った(glDrawArraysInstanced() で描画しようとしている)メッシュを計算します。

http://www.humus.name/index.php?page=Cool&ID=8 . Emil Personのサイトには他にもいろいろな記事があります。
粒子の物理
粒子が地面にぶつかったら跳ね返るようなリアルな感じにしたいと考えているかもしれません。
各粒子に現在の位置と未来の位置との間でレイキャストを適用すれば良いのです。これはPicking tutorialsで学べます。 しかし、これはとても計算コストが高いので、各フレームで各粒子に適応することはできません。
アプリケーション次第ですが、面のセットであると近似して、それぞれの面にのみレイキャストを適応するという方法があります。あるいは、リアルなレイキャストを適応するが、結果をキャッシュしておいて、近くのものと衝突するかをキャッシュで近似するという方法もあります。
まったく別の方法としてはZバッファを幾何学の近似として使う方法です。これは十分な精度で早いです。しかしGPU上でシミュレーションをしなければいけません。なぜならCPU上でZバッファにアクセスできないからです。(できても早くありません。)だからより複雑な方法です。.
これらの方法に関するリンクを書いておきます。
http://www.altdevblogaday.com/2012/06/19/hack-day-report/
GPUシミュレーション
上で言ったように、GPU上で粒子の動きを完璧にシミュレートできます。まだ粒子のライフサイクルをCPU上で管理したいでしょう。
これを行うための選択肢は次のようなものがあります。
- 変換フィードバックを使う。GPUサイドのVBOの頂点シェーダの出力を保存できます。このVBOの新たな位置を保存し、次のフレームで、このVBOをスタート位置として使い、以前のVBOに新たな位置を保存します。
- 変換フィードバックを使わない似た方法。粒子の位置をテクスチャにエンコードして、Render-To-Textureで更新する。
- GPGPUライブラリを使う:CUDAやOpenCLはOpenGLとの橋渡し役をやってくれます。
-
コンピュータシェーダを使う:簡潔な方法ですが、最新のGPUでのみ可能です。
- 簡単化のため、この実装では、ParticleContainerはGPUバッファの更新後に保存しています。これは粒子が正しくは保存されないことを意味します。(1フレームの遅延があります。) しかしそれには気づかないでしょう。メインループをシミュレート、ソート、アップデートに分割すれば修正できます。