チュートリアル16:シャドウマッピング
チュートリアル15では静的な光で囲うライトマップの作りかたを学びました。これは結構いい感じの影を作りますが、動的なモデルには対応していません。
シャドウマップは(2012年)現在、動的に影を作り出す最新の方法です。この方法の良い点は動かすことが簡単という点です。悪い点は”正しく”動かすのがとても難しい点です。
このチュートリアルではまず基本的なアルゴリズムを導入し、欠点を見て、より良い結果を出すような技術を実装していきます。これを書いているのは2012年時点で、シャドウマッピングは現在も重要な研究対象となっています。そのため必要と在れば自分自身で調査できるように、いくつかの指針を示します。
基本的なシャドウマップ
基本的なシャドウマップアルゴリズムは二つのプロセスから構成されています。まずは光の視点からシーンを描画します。各フラグメントでデプスのみを計算します。次に、いつもどおりシーンを描画します。ただし現在のフラグメントがかげの中にあるかを見るための追加のテストを行います。
”影の中にある”かをテストするのはとてもシンプルです。現在のサンプルが同じ位置のシャドウマップよりも遠くにあれば、これはよりライトに近いオブジェクトがあることを意味します。言い換えれば現在のフラグメントは影の中にありま
以下のイメージが原理の理解の助けとなるでしょう。
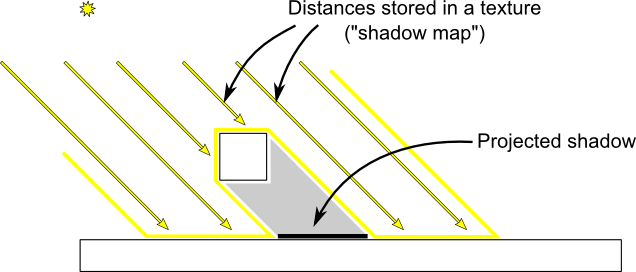
シャドウマップの描画
このチュートリアルでは、ライトの方向のみを考えます。ライトは遠くにあり、すべての光線が平行であるとします。そういうものとして、正射投影行列によりシャドウマップを描画します。正射投影行列とは、パースペクティブを考慮しない透視投影行列のようなものです。つまり、カメラに近くても遠くても同じとしてオブジェクトを見るということです。
描画対象とMVP行列のセットアップ
チュートリアル14で、あとでシェーダからアクセスするために、シーンをテクスチャに描画する方法を学びました。
ここでシャドウマップを格納するために、1024x1024で16ビットのデプステクスチャを使います。通常シャドウマップには16ビットで十分です。この値を変えて、適当に実験してみても良いでしょう。 デプステクスチャを使うのであって、デプスrenderbuffeではありませね。なぜなら後でそれをサンプルする必要があるからです。
// フレームバッファ、0か1かそれ以上のテクスチャと0か1のバッファを再編成する
GLuint FramebufferName = 0;
glGenFramebuffers(1, &FramebufferName);
glBindFramebuffer(GL_FRAMEBUFFER, FramebufferName);
// デプステクスチャ。デプスバッファより遅いが、シェーダで後からサンプルできます。
GLuint depthTexture;
glGenTextures(1, &depthTexture);
glBindTexture(GL_TEXTURE_2D, depthTexture);
glTexImage2D(GL_TEXTURE_2D, 0,GL_DEPTH_COMPONENT16, 1024, 1024, 0,GL_DEPTH_COMPONENT, GL_FLOAT, 0);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glFramebufferTexture(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, depthTexture, 0);
glDrawBuffer(GL_NONE); // カラーバッファが描画されない
// 常にフレームバッファが正しいかをチェックする
if(glCheckFramebufferStatus(GL_FRAMEBUFFER) != GL_FRAMEBUFFER_COMPLETE)
return false;
ライトの位置からシーンを描画するために使うMVP行列は次のように計算できます。
- プロジェクション行列は正射行列で、 X、Y、Z軸それぞれが(-10,10),(-10,10),(-10,20)に位置合わせされた座標内ですべてを囲みます。
- ビュー行列はカメラ空間となるように回転します。ライトの方向は-Zです。( チュートリアル3 参照)
- モデル行列はあなたが決めます。
glm::vec3 lightInvDir = glm::vec3(0.5f,2,2);
// ライトの視点からMVP行列を計算します。
glm::mat4 depthProjectionMatrix = glm::ortho<float>(-10,10,-10,10,-10,20);
glm::mat4 depthViewMatrix = glm::lookAt(lightInvDir, glm::vec3(0,0,0), glm::vec3(0,1,0));
glm::mat4 depthModelMatrix = glm::mat4(1.0);
glm::mat4 depthMVP = depthProjectionMatrix * depthViewMatrix * depthModelMatrix;
// 現在バインドされているシェーダへ変換行列を送ります。MVPユニフォームで。
glUniformMatrix4fv(depthMatrixID, 1, GL_FALSE, &depthMVP[0][0])
シェーダ
シェーダはこの過程ではとてもシンプルです。頂点シェーダは同次座標系で頂点の座標を単に計算するだけです。
#version 330 core
// 入力頂点データ。このシェーダのすべての実行で異なる
layout(location = 0) in vec3 vertexPosition_modelspace;
// メッシュ全体で固定した値
uniform mat4 depthMVP;
void main(){
gl_Position = depthMVP * vec4(vertexPosition_modelspace,1);
}
フラグメントシェーダもシンプルです。 location0のフラグメントのデプスを単に書くだkです。(つまりデプステクスチャです。)
#version 330 core
// 出力データ
layout(location = 0) out float fragmentdepth;
void main(){
// OpenGLがやってくれるので、本当は必要ない
fragmentdepth = gl_FragCoord.z;
}
シャドウマップを描画するのは通常の描画より2倍早くなります。なぜならデプスと色の両方の代わりに、低精度のデプスだけが書かれるからです。GPUではメモリ帯域幅が性能に大きくかかわります。
結果
結果のテクスチャは次のとおりです。

暗い色は小さなzを意味します。だから壁の右上隅はカメラに近いということです。反対に白いところは(同次座標で)z=1を意味します。だからとても遠くにあります
シャドウマップを使う
基本的なシェーダ
ここでいつものシェーダに立ち返ってみましょう。 私たちが計算する各シェーダに対して、シャドウマップの”後”かそうでないかをテストしなければなりません。
これをするためには、現在のフラグメントの位置を、 シャドウマップを作ったときと同じ空間で 計算する必要があります。だから一度いつものMVP行列で変換し、次にデプスMVP行列で変換する必要があります。
ここにちょっとしたトリックがあります。頂点の位置にデプスMVP行列を掛けると同次座標が得られます。それは[-1,1]の範囲です。しかしテクスチャサンプリングは[0,1]の範囲で行われます。
例えば、画面中央にあるフラグメントは同次座標では(0,0)ですが、テクスチャの中央からサンプルする場合はUVは(0,5,0.5)となります。
これはフラグメントシェーダで取り出す座標を直接変更することでも実現できますが、同次座標に次のような行列を掛ける事でより効率的に実現できます。つまり、座標を2分の1にして(対角要素は[-1,1]->[-0.5,0.5])平行移動するような(一番下の行は[-0.5,0.5]->[0,1])行列です。
glm::mat4 biasMatrix(
0.5, 0.0, 0.0, 0.0,
0.0, 0.5, 0.0, 0.0,
0.0, 0.0, 0.5, 0.0,
0.5, 0.5, 0.5, 1.0
);
glm::mat4 depthBiasMVP = biasMatrix*depthMVP;
これで頂点シェーダを書くことができます。以前と同じですが、出力位置を一つから二つに変更します。
- gl_Positionは現在のカメラから見た頂点の位置です。
- ShadowCoordは最後のカメラ(ライト)から見た頂点の位置です。
// クリップ空間での頂点の出力位置:MVP * position
gl_Position = MVP * vec4(vertexPosition_modelspace,1);
// 同じ、ただしライトのビューマトリックス
ShadowCoord = DepthBiasMVP * vec4(vertexPosition_modelspace,1);
フラグメントシェーダはとてもシンプルです。
- texture( shadowMap, ShadowCoord.xy ).zはライトと最も近い遮蔽物との距離です。
- ShadowCoord.zはライトと現在のフラグメントとの距離です。
だから現在のフラグメントが最も近い遮蔽物よりも遠ければ、これは(最も近い遮蔽物の)影の中にあるということを意味します。
float visibility = 1.0;
if ( texture( shadowMap, ShadowCoord.xy ).z < ShadowCoord.z){
visibility = 0.5;
}
この知識を使ってシェーディングを修正します。もちろん環境光の色は変更しません。なぜなら環境光は、影の中に居ようとも、いくつかの向かってくる光をごまかすためにあるからです。(そうしなければ、すべてのものは真っ黒となります。)
color =
// 環境光:向かってくる光をシミュレートする
MaterialAmbientColor +
// 拡散光:オブジェクトの色
visibility * MaterialDiffuseColor * LightColor * LightPower * cosTheta+
// 鏡面光:鏡のように反射するハイライト
visibility * MaterialSpecularColor * LightColor * LightPower * pow(cosAlpha,5);
結果-シャドウアクネ
現在のコードの実行結果は以下のとおりです。明らかにクオリティに問題があります。
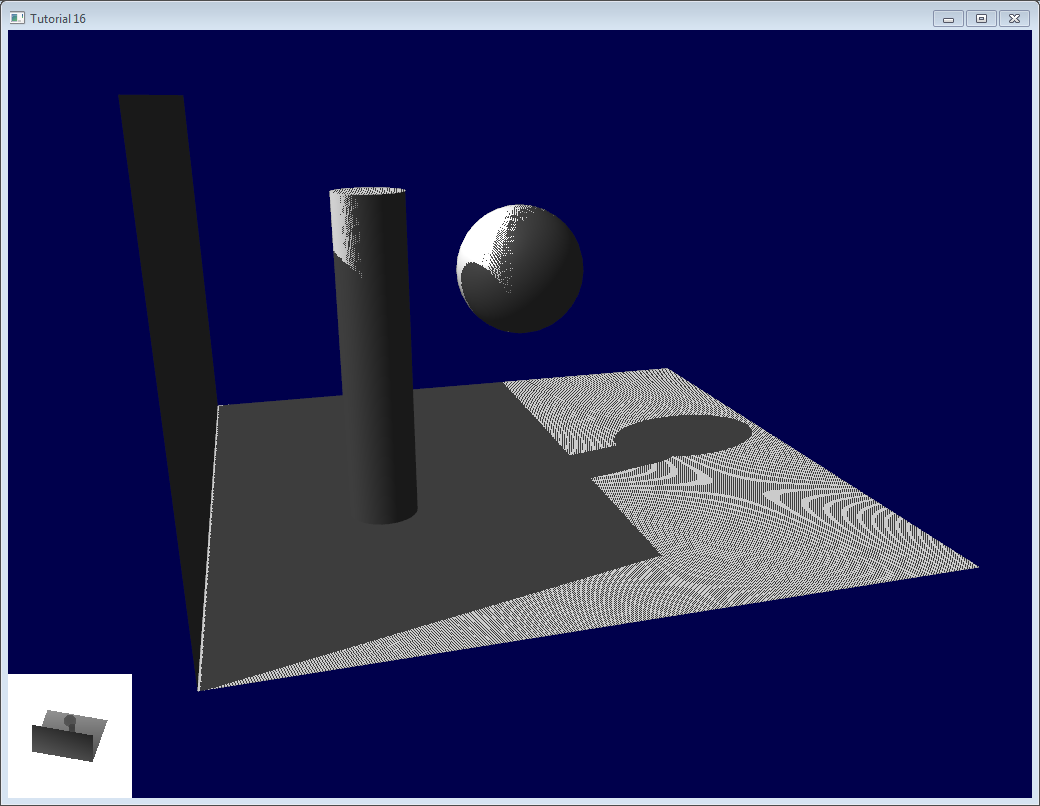
この画像の問題点を見ていきましょう。コードは二つのプロジェクトがあります。shadowmapsとshadowmaps_simpleです。どちらでも好きなほうからはじめて下さい。シンプル版のほうは上の画像と同程度にひどいですが、よりシンプルに理解しやすいです。
問題点
シャドウアクネ
最も明らかな問題は シャドウアクネ と呼ばれています。

この現象はシンプルな画像で簡単に説明できます。
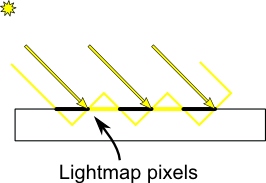
一般的な修正方法はエラーマージンを追加することです。現在のフラグメントの(ライト空間での)デプスがライトマップの値よりも遠くにあれば影ます。これにバイアスを追加します。
float bias = 0.005;
float visibility = 1.0;
if ( texture( shadowMap, ShadowCoord.xy ).z < ShadowCoord.z-bias){
visibility = 0.5;
}
結果はよりよくなったでしょう。

しかしこのバイアスのせいで地面と壁の間の部分がより悪くなりました。さらに、0.005というバイアスは地面にとっては大きすぎますが、曲面では十分ではないようです。シャドウアクネが円柱や球には残っています。
一般的なアプローチは傾斜にしたがってバイアスを修正することです。
float bias = 0.005*tan(acos(cosTheta)); // cosThetaはdot( n,l )で0と1の間にします。
bias = clamp(bias, 0,0.01);
シャドウアクネは曲面以外ではなくなりました。

うまく機能するかは幾何学的な形に依存しますが、もう一つのトリックとしてはシャドウマップのバックフェイスのみ描画するという方法があります。これは厚い壁のような特別な幾何学(次のセクション-ピーターパニング)をもつことを強制します。しかし少なくとも、影の中にある面にアクネはあるでしょう。
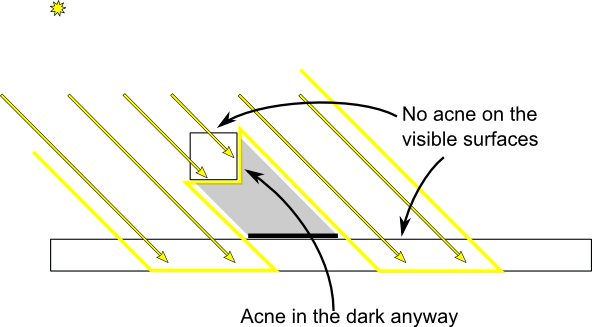
シャドウマップを描画するとき、前面向きの三角形をカリングします。
// シェーダでバイアスは使いません。しかし代わりに、小さな距離によって既に前面から分離されているバックフェースを描画します。
// (もし幾何学的な形がこのように作られているなら。)
glCullFace(GL_FRONT); // 前面をカリング->後ろ向きの三角形のみ描画する。
シーンを描画するとき普通に描画します。(バックフェースカリング)
glCullFace(GL_BACK); // 背面をカリング->表向きの三角形のみ描画する。
この方法はバイアスとともにコードで使われています。
ピーターパニング
既にシャドウアクネはありませんが、地面の影はまだ間違ったままです。壁が少し浮かんでいるようになっています。それゆえピーターパニング(Peter Panning)と呼ばれています。実は、バイアスを加えるとより悪化します。

これは簡単に修正できます。単純に薄い形を避ければ良いだけです。これには二つの利点があります。
- 一つ目は、ピーターパニングを解決できます。厚さがバイアスよりも大きければ、すべてに適応できます。
- 二つ目は、ライトマップを描画するときにバックフェースカリングを有効にできます。なぜなら、ライトに向かっている壁のポリゴンがあるからです。これによりもう一方を隠してしまいます。そしてバックフェースカリングで描画されません。
欠点はより多くの三角形を描画しなければいけないことです。(1フレームで2倍!)

エイリアシング
これらの二つのトリックを使っても、影の境界にはエイリアシングがあることに気づくでしょう。言い換えれば、あるピクセルが白で次のピクセルは黒で、間にスムーズにする変換が入っていません。

PCF
最も簡単な改善法はシャドウマップのサンプルタイプを sampler2DShadow に変えることです。これはシャドウマップから一度サンプルするとき、ハードウェアが周りのテクセルも同様にサンプルし、それらと比較し、比較結果のバイリニアフィルタリングによって[0,1]の範囲の浮動小数点を返します。
例えば、0.5は二つのサンプルが影の中にあり、二つのサンプルが光の中にあることを意味します。
これはフィルタされたデプスマップの単一のサンプルと同じではありません。比較はいつもtrueかfalseで返します。PCFは4つの”trueかfalse”の補間を与えます。

ご覧のように、影の境界はスムーズになりましたが、シャドウマップのテクセルはまだ見えています。
ポアソンサンプリング
簡単な方法はシャドウマップをサンプルする回数を一回からN回にするという方法です。PCFとの併用により、たとえ小さなNだとしても、とても良い結果を与えてくれます。ここに4サンプルのコードを示します。
for (int i=0;i<4;i++){
if ( texture( shadowMap, ShadowCoord.xy + poissonDisk[i]/700.0 ).z < ShadowCoord.z-bias ){
visibility-=0.2;
}
}
poissonDiskは定数配列で次のように定義されています。
vec2 poissonDisk[4] = vec2[](
vec2( -0.94201624, -0.39906216 ),
vec2( 0.94558609, -0.76890725 ),
vec2( -0.094184101, -0.92938870 ),
vec2( 0.34495938, 0.29387760 )
);
このように、いくつのシャドウマップのサンプルが通過するかによりますが、作成されるフラグメントは多少なりとも暗くなります。

700.0という定数はどの程度サンプルを”広げるか”ということを定義しています。広げるのがあまりにも小さいと再びエイリアシングになるでしょう。あまりにも大きすぎれば次のようになるでしょう。バンディング(このスクリーンショットはPCFは使っていません、しかし代わりに16サンプルを使っています。) *


ポアソンサンプリングの階層化
各ピクセルで異なるサンプルを選ぶことでこのバンディングは取り除けます。主に二つの方法があります。階層ポアソンあるいは回転ポアソンです。階層は異なるサンプルを選び、回転は同じサンプルを使うが違うように見せるめにランダムに回転させます。このチュートリアルでは階層版を説明します。
前のバージョンと違う点は poissonDisk をランダムにインデックスする点だけです。
for (int i=0;i<4;i++){
int index = // 0から15のうちのランダムな数字、各ピクセル(と各i)で違うようにする。
visibility -= 0.2*(1.0-texture( shadowMap, vec3(ShadowCoord.xy + poissonDisk[index]/700.0, (ShadowCoord.z-bias)/ShadowCoord.w) ));
}
次のコードのように[0,1[の間の乱数を生成します。
float dot_product = dot(seed4, vec4(12.9898,78.233,45.164,94.673));
return fract(sin(dot_product) * 43758.5453);
このケースでは(4つの異なる点をサンプルするために)seed4はiのコンビネーションです。そしてgl_FragCoord(画面上のピクセルの位置)あるいはPosition_worldspaceを使います。
// -ピクセルの画面上の位置に応じて、ランダムにサンプルしたもの
// バンディングはありません。しかしカメラが移動すると影も動きます。
int index = int(16.0*random(gl_FragCoord.xyy, i))%16;
// - ワールド空間でのピクセルの位置に応じてランダムにサンプルしたもの
// 位置は大きなエイリアシングを避けるためにミリメータに直されます。
//int index = int(16.0*random(floor(Position_worldspace.xyz*1000.0), i))%16;
これは上の画像のようなパターンを作ります。ただし、良くできたノイズはあまりこのようなパターンにはなりません。
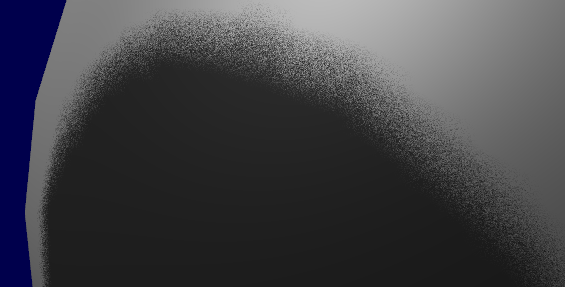
tutorial16/ShadowMapping.fragmentshaderの3つの実装例を見てください。
さらに先へ
これらのトリックのほかにも数多くの影を改善する方法があります。 ここでいくつか紹介します。
アーリーベイリング
各フラグメントで16サンプル取る代わりに、離れた4サンプルを取ります。もしそのすべてが光の中あるいは影の中にあれば、回りの16サンプルすべてが同じような状況にあると考えられるでしょう。もしすべてが同じでなければ、影の境界にあるので16サンプルを取る必要があります。
スポットライト
スポットライトを扱うには少し変更を加えるだけで良いです。最も明らかな変更は正射投影行列をパースペクティブ投影行列に変えることです。
glm::vec3 lightPos(5, 20, 20);
glm::mat4 depthProjectionMatrix = glm::perspective<float>(glm::radians(45.0f), 1.0f, 2.0f, 50.0f);
glm::mat4 depthViewMatrix = glm::lookAt(lightPos, lightPos-lightInvDir, glm::vec3(0,1,0));
同じように、しかしパースペクティブ円錐台を正射円錐台の変わりに使います。texture2Dprojをパースペクティブ分割のために使います。(チュートリアル4を見てください。)
二つ目のステップはシェーダにおいてパースペクティブを考慮に入れることです。(チュートリアル4を見てください。ナットシェルの中は、パースペクティブ投影行列はもはやパースペクティブしないでしょう。これは射影された座標をwで割ることによってハードウェアによって行われます。ここで、シェーダ内で変換をエミュレートします。だからパースペクティブ分割を自分自身でします。ところで、正射投影行列は常にw=1の同次ベクトルを生成します。そのためどんなパースペクティブも作り出しません。)
GLSLで行うには二つの方法が在ります。二つ目はtextureProjという組み込み関数を使います。しかし二つの関数はまったく同じ結果を出します。
if ( texture( shadowMap, (ShadowCoord.xy/ShadowCoord.w) ).z < (ShadowCoord.z-bias)/ShadowCoord.w )
if ( textureProj( shadowMap, ShadowCoord.xyw ).z < (ShadowCoord.z-bias)/ShadowCoord.w )
ポイントライト
同様に、しかしデプスキューブマップを使った方法を紹介します。キューブマップは6つのテクスチャがセットに成ったもので、立方体の各面に対応しています。さらにいうと、通常のUV座標の酔うにはアクセスしません。かわりに方向を表す3次元ベクトルによってアクセスします。
デプスは空間内のすべての方向に格納されています。これにより、ポイントライトの周辺で影をキャストすることを可能にします。
ライトの組み合わせ
このアルゴリズムはいくつかのライトを取り扱います。しかし各ライトはシャドウマップを生成するために追加のシーンの描画が必要となることを頭に入れて置いてください。これは影を適用するときに多くのメモリを要求します。そして帯域幅の上限にすぐ達してしまうでしょう。
自動ライト円錐台
このチュートリアルでは、全シーンを含むライト円錐台を手作業で作ります。ここでは制限された例ですが、それは避けるべきです。もしマップが1km x 1kmだとすると、1024x1024のシャドウマップの各テクセルは1平方メートルを扱います。ライトの射影行列は可能な限り締まった状態になります。
スポットライトでは、この範囲を簡単に変更できました。
太陽のような指向性ライトではもう少しトリッキーです。それらのライトはシーン全体を照らそうとします。ライト円錐台を計算する方法は次のようになります。
潜在影レシーバー(略してPSRs)は同時にライト円錐台とビュー円錐台とシーン領域に所属しているオブジェクトです。その名前が示すように、これらのオブジェクトは影の影響を受けやすいです。それらはカメラとライトによって可視化されます。
潜在影キャスター(略してPCFs)はすべての潜在影レシーバーと、それらとライトの間にあるすべてのオブジェクトを指します。(オブジェクトは見えないかもしれませんが、可視化した影にキャストできます。)
だから、ライト射影行列はすべてかしかでき、遠くにあるものを取り除き、その領域を計算できます。ライトと領域の間にあるオブジェクトを加え、あらたな領域を計算します。(しかしこのとき、ライトの方向に位置合わせされます。)
これらのセットの実際の計算は凸包インターセクションの計算が関わってきますが、実装はより簡単にできます。
この方法はオブジェクトが円錐台から消えたときポピングを起こします。なぜならシャドウマップの解像度が急に増えるからです。カスケードシャドウマップはこのような問題がありません。しかし実装するのが難しく、ずっと値をスムージングすることによって補い続けなければなりません。
指数シャドウマップ
指数シャドウマップは、影の中にあるがライトの面の近くにあるフラグメントが実はその中間のどこかにあるものと仮定することで、エイリアシングを制限する方法です。これはテストが二値ということを除けばバイアスと似ています。フラグメントはライトの面との距離が増えれば増えるほどより暗くなります。
これは明らかにずるく、二つのオブジェクトが重なったとき乱れが現れます。
ライト空間パースペクティブシャドウマップ
LiSPSMはカメラ付近でより正確に成ろうとするためにライト射影行列を微調整する方法です。これは特に円錐台が争うときに重要となります。あなたが向いてる方向とスポットライトが向いてる方向が反対のときを意味します。ライト付近で多くのシャドウマップの精度があります。つまりあなたから遠くなればカメラの近くの解像度が低くなります。
しかしKLiSPMは実装が難しく、詳しくは参考文献を見てください。
カスケードシャドウマップ
CSMはLiSPSMと同様の問題を扱いますが、異なる方法で対処します。ビュー円錐台の異なる部分でいくつか(2つから4つ)の基本的なシャドウマップを使います。最初のシャドウマップが最初の数メートルを扱いうため、とても狭い範囲の解像度がとてもよくなります。次のシャドウマップはより遠くのオブジェクトを扱います。最後のシャドウマップはシーンの大部分を扱いますがパースペクティブのため、近くにあるものほど可視化には重要ではありません。
カスケードシャドウマップは2012年時点では、複雑度とクオリティの比が最もよいものだといえます。これは多くのケースで使われています。
結論
これまで見てきたようにシャドウマップは複雑です。毎年新たな種類の実装が出てきます。ただし今はまだ完璧な解決策はありません。
幸運にも上で上げた手法は組み合わせが可能で、ライト空間パースペクティブでカスケードシャドウマップをつかい、PCFでスムージングして…といったことが可能です。これらのすべての手法を実験してみてください。
結論として可能なときはあらかじめ計算したライトマップを使い、動的に動くものにのみシャドウマップを使うべきだといえます。覚えておいて欲しいのは視覚的なクオリティはどちらも同じだということです。完璧な静的な環境とひどい動的な影はどちらかだけに絞るのは良い選択ではありません。